This article talks about:
- The Problem: Your team spends hours manually correlating CDN logs, SSAI traces, and QoE beacons during live streaming incidents - while viewers churn and ad impressions are lost.
- The Blocker: Expensive, query-time correlation in traditional observability platforms can't handle high-cardinality dimensions (channel x region x device x POP) fast enough to matter.
- The Solution: A stream-first architecture that pre-computes causal chains as data arrives, delivering a root cause diagnosis in minutes, not hours and at a fraction of the cost.
- The Model: This approach works alongside your existing stack (Datadog, New Relic, etc.) as a hybrid model, not a replacement.
- The Outcome: Drastically faster incident response (MTTR) protects revenue and ad impressions, while a smaller data footprint reduces total cost of ownership (TCO).
Live streaming doesn't give you the luxury of time. When startup latency spikes or rebuffer ratios climb, viewers churn in seconds and ad impressions evaporate. Your monitoring stack shows you symptoms across six dashboards, but the blocker is always the same: time-to-why.
Until you can say which layer failed, which cohort it hit, and where in your stack, you can't route traffic, pre-warm cache paths, bypass failing ad pods, or escalate to vendors. Minutes lost are revenue lost.
The brutal reality: you're paying to ingest and store terabytes of raw logs - not because you need all of it daily, but because when incidents hit, you need to reconstruct causality from scratch.
A Friday Night Fire Drill
Consider a real-world example from a Friday night sports broadcast:
- Symptom: The rebuffer ratio for "Channel Sports1" jumps to 1.1% for viewers in US-East on Roku devices.
- Concurrent pages show: CloudFront 5xx% is up at the distribution-level, MediaTailor ad-decision p95 is elevated, and the S3 origin is showing a brief 503 SlowDown.
None of these alone tells you why. They're disconnected symptoms with different timestamps, aggregation windows, and dimensional keys.
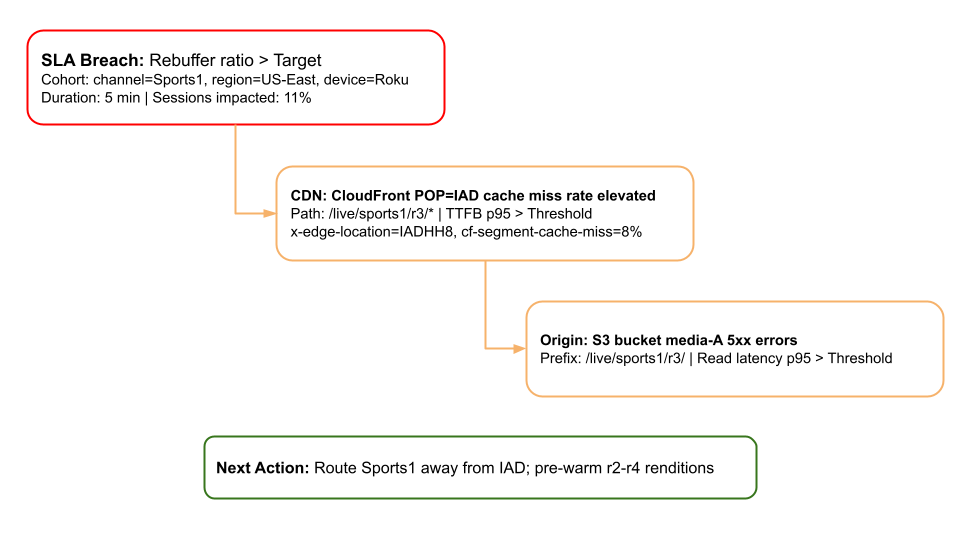
What actually happened: A routing flap shifted traffic to POP=IAD. An automated cache purge combined with short-lived signed URLs (60s TTL) left /live/sports1/r3/ cold only at that POP. Roku devices' ABR logic preferentially selected r3 early in playback, so that device cohort hit the cold path hardest.
The root cause was a precise intersection of dimensions: (channel=Sports1, region=US-East, device=Roku, POP=IAD, path=/r3) had elevated cache misses, leading to a TTFB p95 > 1200ms and rebuffering for that specific cohort.
How you find this today:
- Notice the rebuffer spike in the QoE dashboard.
- Check CloudFront metrics - distribution-level errors are up (Region=Global).
- Export CloudFront real-time logs, filtering by the timestamp window.
- Join logs with QoE beacons on URI stem and timestamp (brittle under load).
- Group by POP x device x path to isolate the outlier cohort.
- Cross-reference with origin metrics and purge logs.
- Total time: 45-90 minutes.
By then, the damage is done. Viewers have churned. Ad impressions are lost.
The Architectural Flaw: Why Correlation Happens Too Late
That fire drill is a direct result of an architectural mismatch. Your stack spans multiple layers: CDNs (CloudFront, Akamai, Fastly), origin packagers, SSAI platforms (MediaTailor, FreeWheel/Google Ad Manager), DRM services, and client players across countless device types. When QoE degrades, the root cause could be anywhere.
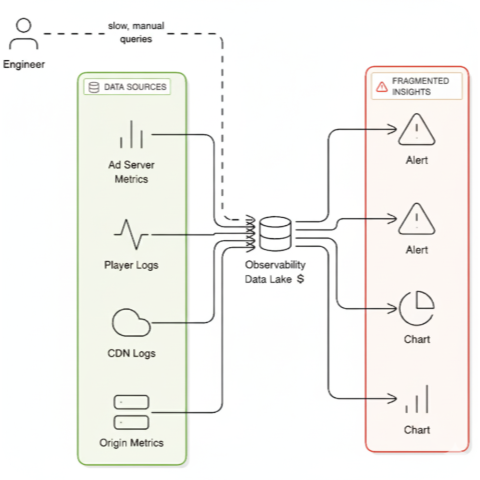
Live streaming exposes this observability problem with brutal clarity for several key reasons:
- High Cardinality: The combination of dimensions - channel x region x device x POP x rendition path x ad content-creates a permutation explosion. Pre-aggregating loses the signal you need to isolate the blast radius. Querying on-demand is slow and expensive.
- No Stable Correlation ID: A single session lacks an end-to-end trace ID that spans from the Player to the CDN, origin, and SSAI/DRM. You're forced to synthesize joins using brittle keys like URI stems and headers.
- Cross-Source Correlation is Required: Signals from AWS CDN metrics, origin telemetry, SSAI logs, and QoE beacons must be joined in real-time. Query-time joins across billions of log lines don't finish before your viewers leave.
- The Hot-Log Trap: To make this slow correlation even possible, you keep real-time logs from CloudFront, SSAI, and DRM fully indexed in your observability platform. You're paying 100% of the storage costs to support the 0.01% of queries that happen during incidents.
A Different Approach: Correlation Before Storage
The architectural shift is subtle but fundamental: compute causality as data streams in, not after it's stored.
Instead of storing raw telemetry and joining it at query time, you correlate it across sources in real-time using stateful stream processing. Then, you store only the high-value causal incidents and their supporting evidence.
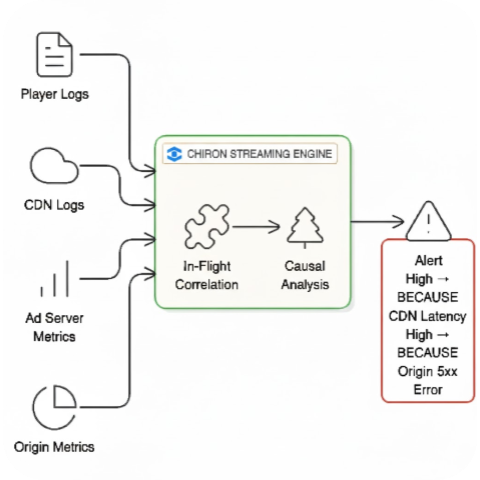
Here's what that architectural trade-off looks like in practice:
Traditional Architecture (Storage-First):
- Correlation: Happens at query time via slow, expensive JOIN operations.
- Compute Scales With: Total data volume and query complexity.
- Storage Scales With: Raw telemetry volume and retention period.
Stream-First Architecture:
- Correlation: Happens once, as data arrives, using a stateful engine.
- Compute Scales With: Incident volume, not total telemetry volume.
- Storage Scales With: High-value incident artifacts, not raw telemetry.
The resource advantage isn't linear - it's exponential. You're computing causality on hot data paths where context is implicit, not reconstructing it from cold storage where every correlation requires full scans or incurring high indexing cost.
The result? The alert that lands in your pager is no longer a symptom. It's a diagnosis.
The Hybrid Model: Coexistence, Not Replacement
Here's the critical insight: you don't need to replace your existing observability stack. Datadog, New Relic, Dynatrace - they're excellent at what they do:
- Historical trend analysis and long-term retention
- Ad-hoc exploration when you have time to investigate
- Custom dashboards for team-specific workflows
- APM, RUM, and synthetic monitoring
- Integration ecosystems you already rely on
What they're not architected for: real-time cross-source correlation at streaming scale with high-cardinality dimensions. That's a fundamentally different computational problem that requires fundamentally different primitives.
The division of labor:
Chiron handles:
- Real-time ingestion of high-velocity telemetry (CloudFront RTL, origin metrics, SSAI logs, DRM traces, QoE beacons)
- Stateful correlation across sources with cohort-aware windowing
- Causal chain construction linking symptoms to root causes
- Structured incident emission with blast radius and evidence
Your existing platform handles:
- Dashboards and visualization
- Historical analysis and trend detection
- Ad-hoc queries and exploration
- Team collaboration and workflow automation
Data flow:
- Chiron ingests raw telemetry streams for real-time correlation
- Chiron emits structured incidents to your alerting pipeline (PagerDuty, Slack)
- Chiron mirrors only incident-scope data to your observability platform for post-incident deep-dives
- Your platform remains the system of record for trends and exploration
The win-win:
MTTR improvement: Incidents arrive with causal chains pre-computed. Your on-call engineer sees root cause, blast radius, and recommended actions in the first page, not after 90 minutes of dashboard surfing and log correlation.
TCO reduction: You're no longer keeping full CloudFront real-time logs, SSAI logs, and DRM traces hot in expensive storage just to enable causality during incidents. Correlation happens at ingest; only incident artifacts and evidence are retained long-term. Your baseline hot-log volume drops dramatically while incident response actually gets faster.
You keep your dashboards. You keep your integrations. You keep your ad-hoc query capability.
You simply add what's missing: pre-computed causality at streaming scale.
The Real Question
Live streaming is economically sensitive to downtime, but the underlying challenge is universal.
The conventional wisdom says: "Pay for better monitoring to reduce incidents." The reality is: you're already monitoring everything. You don't need more dashboards. You need the first page to be the right page - with causality, blast radius, and next action already computed. So ask yourself two questions:
- How many hours does your team spend per incident correlating CDN logs, application metrics, service traces, and client-side telemetry by hand?
- How much are you spending on hot log retention just to enable that manual correlation when incidents hit?
Stream-first architecture isn't about replacing your observability stack. It's about doing the expensive computational work once, as data arrives, instead of repeatedly at query time. The result is faster incident response and lower infrastructure costs. Not one at the expense of the other.
Stop paying to store everything just to find one thing. Correlate first. Store what matters.
Chiron is a streaming-first observability platform built from the ground up to deliver the root cause, not just another alert, helping teams dramatically reduce MTTR while keeping TCO in check. Visit chironvision.ai to learn more and book a demo to see how Chiron strengthens SLA reliability across real-time, mission-critical systems.
About the author:
Punit Agarwalla is the co-founder of Chiron, a stream-first observability company changing how observability is done for latency-sensitive systems. Before founding Chiron, Punit worked on Google's streaming and ad-tech products and at the video streaming unicorn, Philo, giving him first-hand experience with the pain points of large-scale video delivery.